
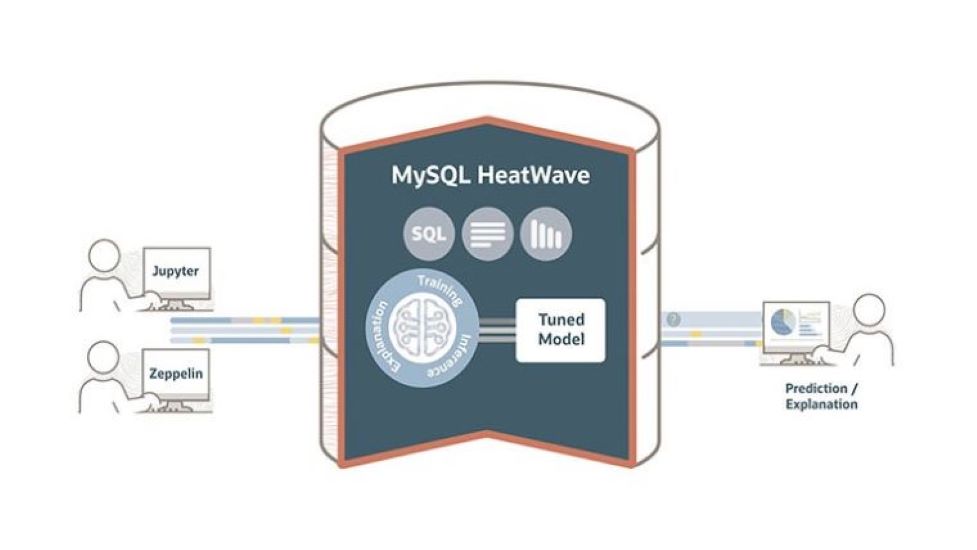
The News: Oracle announced that Oracle MySQL HeatWave now supports in-database machine learning (ML) in addition to the previously available transaction processing and analytics, providing users a new MySQL cloud database service solution to do so. MySQL HeatWave ML is designed to fully automate the ML lifecycle and store all trained models inside the MySQL database, eliminating the need to move data or the model to a machine learning tool or service. Eliminating ETL reduces application complexity, lowers cost, and can improve security of both the data and the model. HeatWave ML is included with the MySQL HeatWave database cloud service in all 37 Oracle Cloud Infrastructure (OCI) regions. Read the Oracle Press Release here.
MySQL HeatWave: Teaching the Competition a Lesson in ML
Analyst Take: Oracle’s MySQL HeaWave ML announcement represents the third major release of MySQL HeatWave in just over 15 months. The MySQL HeatWave launch in December 2020 united OLTP with a query accelerator, giving customers real-time analytics. The MySQL Heatwave launch in summer 2021 delivered MySQL Autopilot, 64 node scalability, introduced HeatWave scale out storage for reloading data and improved performance advances which the company says has resulted in customers migrating from AWS Aurora, RDS, Redshift, Teradata, SAP HANA, and Google BigQuery platforms. Throughout these migrations, Oracle prioritized MySQL customer feedback with a view toward further improving the overall MySQL experience. As a result, four major areas of prioritization were identified, with in-database machine learning as the top customer request.
While I will examine several of HeatWave ML’s features, model explanation is critical for enterprise workloads. This is particularly the case when explanations are integrated with the training pipeline along with model-agnostic techniques, which can explain any HeatWave ML model. From my perspective, the ML explanation of any and all models in HeatWave ML can help organizations in fulfilling key organization-wide objectives such as:
- Regulatory compliance: May imply right to an explanation for algorithms-affecting users
- Fairness: By allowing validation that predictions are unbiased
- Repeatability: Ensures that small changes in input do not lead to large changes or disruptions in the explanation
- Causality: Allows verification that only casual correlation between features and predictions are selected
- Trust: Interpretable explanations encourage ML-based protection
I see these new ML explanations in HeatWave providing differentiation opportunities for Oracle across usability and interpretability, quality, along with scalable performance. For usability and interpretability, the model agnostic techniques enable explanation of all HeatWave models that do not require a reference dataset when performing explanations. As such, intuitive explanations assist users in determining which factors contribute most to a prediction.
Quality is improved by leveraging dataset characteristics which provide repeatable and stable explanations and support novel improvements that more accurately explain the model’s behavior. Improved repeatability means less variance between explanations and lower error nearby to the sample to explain. Performance and scalability are augmented, since explanations scale linearly, and not exponentially, with the number of features. This results in real-time explanations that are possible due to distribution of work among workers and cores.
MySQL HeatWave ML: Competitive Advantages Against Rivals
As I explore qualitative and quantitative comparisons, note that I am basing my assessment on data presently made available to us. In this case, I am using all the ML Benchmarks and all the TPC-DS benchmarks, including all the scripts, configs, and details, that are posted on GitHub for full transparency, allowing anyone to replicate them for verification. The TPC-DS benchmarks were performed by an independent third-party benchmarking organization and the ML benchmarks were performed by MySQL HeatWave Engineering.
Exploring this data, in direct comparison to rival cloud DB services, I am impressed that HeatWave ML demonstrates clear competitive differentiation against Amazon Redshift ML and Snowflake ML across eight key features. Note that These features include AutoML, model and prediction explanations, user-facing API, user control of ML functionality, data/model locality, data available, supported number of nodes for training, and data sampling as indicated in the chart below:

Image Credit: Oracle
For example, HeatWave ML natively supports AutoML, including integration and completion criteria capabilities, and is convergence-based. In contrast, Redshift ML requires users to use Amazon SageMaker with the meter running as its use is based on time budgets. Snowflake ML does not support AutoML at all, requiring users to rely on third-party libraries or chargeable services. Both Redshift ML and Snowflake ML require users to move both data and models outside of the database, which increases security risks by exposing more surface area attack possibilities and makes data stale by the time all the data movement and manipulation is completed. Consideration must also be given to costs incurred when using separate ML tools and the learning curves associated therewith, which can result in lost employee productivity when evaluating potential solutions.
For data sampling, HeatWave ML brings intelligent sampling, whereas Redshift ML uses random sampling and Snowflake again compels users to resort to third-party libraries. From my perspective, demonstrating such differentiators can broaden HeatWave’s addressable market, win more mindshare across the cloud DB ecosystem, and accelerate Oracle sales cycles.
MySQL HeatWave ML: Let the Competition Begin
I see HeatWave ML achieving solid differentiation across a wide range of top cloud DB services selection criteria that augment the competitive advantages across the eight key features. These selection criteria include self-tuning, training time, pause & resume, costs, and other enhancements.
In the area of tuning, for example, it’s beneficial that HeatWave ML is self-tuning, relieving users of the uncertainties of pre-selecting parameters. Conversely, Amazon Redshift ML requires the user to specify the desired run time and maximum number of cells, including the headache of using larger values which can trigger higher costs. Users might face the added frustration of not getting a better model by simply spending more.
Based on testing by Oracle, and available for anyone to replicate on GitHub, HeatWave ML is both 25X faster and more accurate than Redshift ML at 1% of the cost, based on the default training time that the Amazon solution delivers as indicated in the chart below:

Image Credit: Oracle
Based on the default training time required by Redshift, it appears as though HeatWave ML is also more affordable than Redshift ML, as shown below.

Image Credit: Oracle
The HeatWave ML differentiation cause is furthered by providing automated tuning and training of models, especially in the scaling of challenging AutoML applications. Each stage of a given pipeline has unique considerations for parallelism, which entails tradeoffs between runtime, accuracy, and scalability. For instance, iteration-free pipelines with fewer trials improve runtime but trades off parallelism, while reduced synchronization points in AutoML pipeline trades off accuracy for improved scalability. Likewise, convergence of the pipeline creates fewer trials at the end of the query, trading off scalability for faster runtime. In sum, I credit Heatwave ML’s better performance across larger cluster sizes as validating its value in handling AutoML scalability as shown in the following chart provided by Oracle:

Image Credit: Oracle
These cost and performance differentiators make HeatWave ML a very attractive offering for customers of all sizes.
MySQL HeatWave ML: Real-Time Elasticity Further Fuels the Differentiation Engine
From my point of view, supporting real-time elasticity is a key feature that cloud DB users are increasingly demanding when aligning their key database analytics scalability requirements. I consider the most important real-time elasticity features as encompassing:
- Availability: All operations (queries, DMLs, load) are permitted on-cluster during resizing
- Flexibility: Upsize of downsize to any number
- Balanced: Data across nodes is balanced after resize
- Performant: Minimal data movement during resize. Data loaded at object store bandwidth
- Predictable: Resize time is constant and predictable

Image Credit: Oracle

Image Credit: Oracle
Through delivering these features across the board, I regard MySQL HeatWave as providing the fully available up/down scaling to any size cluster, which helps Oracle stand out from the competition. Snowflake, for example, provides instant elasticity but with delayed loading of data on first query. Of equal concern, Snowflake only allows scale up or down in exponentially large cluster sizes such as threefold or fourfold cluster sizes (i.e., 64 to 128 CPUs). This limits the ability of simpler queries to fully utilize the large cluster as well as shoehorning customers into only up/down scaling the DB through a pre-determined, “shoe sizing” approach which doubles the cost. With Snowflake, if I need a pair of size 7 shoes but Foot Locker only has size 12, then I’m spending two to three times the money and my shoes resemble those of former employees at the Barnum & Bailey Circus.
Redshift ML resizing can take 10 to 15 minutes during which writes are not allowed, which can result in constraining user flexibility. In addition, during resizing, queries can be held back or timed out and if the user is not prepared with a snapshot, resizing can take even longer to implement. Adding to the potential for additional user frustration, any resulting data-skew must be identified manually and resolved with a classic resize, which can take hours or days. These are, of course, difficulties that any cloud DB user would prefer to avoid altogether.
AWS Redshift RA3 provides compute instances of 4, 12, and 48 vCPUs. When an organization needs 17 CPUs, they must buy 48—there is no other choice. This is yesteryear’s antiquated approach to cloud databases, and I believe not how customers want to be treated going forward. I can’t imagine AWS not modifying this at some point in the future, as it only makes sense.
Also integral to the differentiation of MySQL HeatWave is the doubling of the data that can be processed per node, reducing costs by about 50%:

Image Credit: Oracle
MysQL HeatWave ensures that users experience no impact on load time when compression is in use, including reading into HeatWave memory and writing to object store processes. This is achieved by offloading compression to the HeatWave cluster. For example, when 4MB chunks are compressed and multiple compressed chunks are coalesced to form 4 MB chunks which are persisted on object store, the 4MB chunks result in maximized I/O performance.

Image Credit: Oracle
In addition, pause and resume functions now include instantaneous stop and constant time resume. To achieve this, HeatWave continuously writes data to object store, which enables instantaneous stop on HeatWave, also freeing up HeatWave compute resources. The HeatWave cluster also provisions and restores data through saved tables, encodings, and statistics that provide predictable time to resume capabilities. Customers can now pause HeatWave during the night or weekends when developers are not using the database, further reducing costs.
MySQL HeatWave: Let the Price/Performance Competition Begin
As a capstone, I believe HeatWave ML offers some competitive differentiation benefits including price/performance advantages over Amazon Redshift, Snowflake, Google Big Query, and Azure Synapse that make the Oracle offering consideration worthy. Based on the data made available to me, HeatWave provides better price-performance of 4.8x in relation to Redshift, 14.4x better than Snowflake, 12.9x better than BigQuery, and 14.9x better than Synapse:

Image Credit: Oracle
As such, I see the very real possibility of HeatWave ML’s value proposition gaining broader consideration and making further inroads across the cloud DB services ecosystem due to HeatWave’s demonstrable price-performance competitive edge.
Key Takeaways on Oracle MySQL HeatWave ML Debut
The HeatWave ML news represents a three-pronged attack on the competition — with transaction processing, analytics, and now machine learning all engineered inside a single MySQL DB service. Why would you use two different databases, two to three different ETL tools and risk the movement of both data and models when you can do it with one database? The AWS and Snowflake approach to ML is analogous to going to the local auto parts store to buy a steering wheel, brakes, tires, and a transmission and then trying to put a car together yourself when you could just order one from Tesla online and be done with it. And therein lies the advantage for Oracle MySQL HeatWave ML.
From my perspective, the question for developers is: “Are you looking to be more productive, or spend time haggling with ETL tools and shuffling data back and forth?” The question for those in organizations that manage cloud IT expenditures consists of: “Are you in the business of making up for deficiencies in public cloud DB services or focusing on your core business competencies? And consider what will you do when approached by senior management when they ask—and eventually, they will ask—why are you spending 5-10x the cost on multiple services instead of one DB?” Based on what I’ve seen thus far, MySQL HeatWave represents the fiscally responsible approach to cloud databases while AWS Redshift and Snowflake represent the fiscally reckless approach.
I believe the new MySQL HeatWave ML offering demonstrates that Oracle has delivered more cloud database innovations over the last 15 months than most cloud database vendors have delivered in the last decade. From my point of view, the in-database HeatWave ML puts Redshift ML and Snowflake on notice. Are these solutions more like yesterday’s tech in terms of engineering, performance, and cost? If they’re slower and more expensive, chances are the answer is yes. It’s clear that Oracle is innovating in cloud databases and gaining distinct competitive advantages over rivals. Will the competition respond or stagnate? Amazon has 15 overlapping specialized cloud DB services, and it’s no doubt lucrative when customers use multiple services, for example Redshift ML and SageMaker for machine learning, forcing chargeable ETLs and data movement. But it’s safe to say that Amazon is not known for sitting still for long, and I would guess that cloud database innovation is definitely on the table for the AWS team.
Snowflake continues its single-minded pursuit of analytics and likewise forcing customers to ETL, but to a chargeable third-party service.
Oracle’s MySQL HeatWave is now positioned to drive increased innovation in the cloud DB market and force the competition to examine their offerings both in terms of technology and in terms of pricing — all of which will benefit customers in the end.
Disclosure: Futurum Research is a research and advisory firm that engages or has engaged in research, analysis, and advisory services with many technology companies, including those mentioned in this article. The author does not hold any equity positions with any company mentioned in this article.
Analysis and opinions expressed herein are specific to the analyst individually and data and other information that might have been provided for validation, not those of Futurum Research as a whole.
Other insights from Futurum Research:
Oracle Unleashes Multi-VM Autonomous Database on Exadata Cloud@Customer to Transform Data Management
Oracle Database API for MongoDB: Running MongoDB Workloads on Oracle Cloud Infrastructure
Image Credit: VentureBeat
The original version of this article was first published on Futurum Research.

Ron is an experienced research expert and analyst, with over 20 years of experience in the digital and IT transformation markets. He is a recognized authority at tracking the evolution of and identifying the key disruptive trends within the service enablement ecosystem, including software and services, infrastructure, 5G/IoT, AI/analytics, security, cloud computing, revenue management, and regulatory issues.